Come see our oral!
Talk 1: CURE
Oral Session 6C
Medical Vision
14:00–15:15
Mile High Ballroom 1A–2A
Come see our oral!
Talk 1: CURE
Oral Session 6C
Medical Vision
14:00–15:15
Mile High Ballroom 1A–2A
Visit our poster!
Poster 11: CURE
Poster Session 6
ExHall A
15:30–17:30
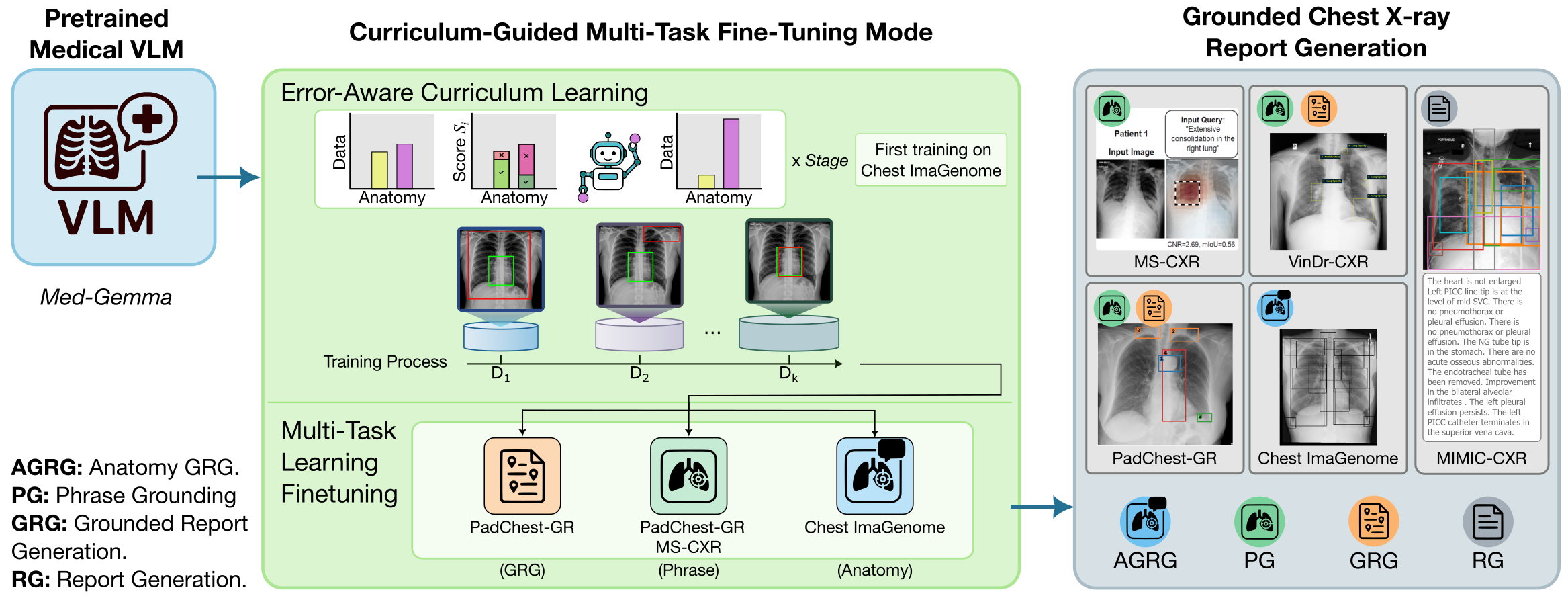
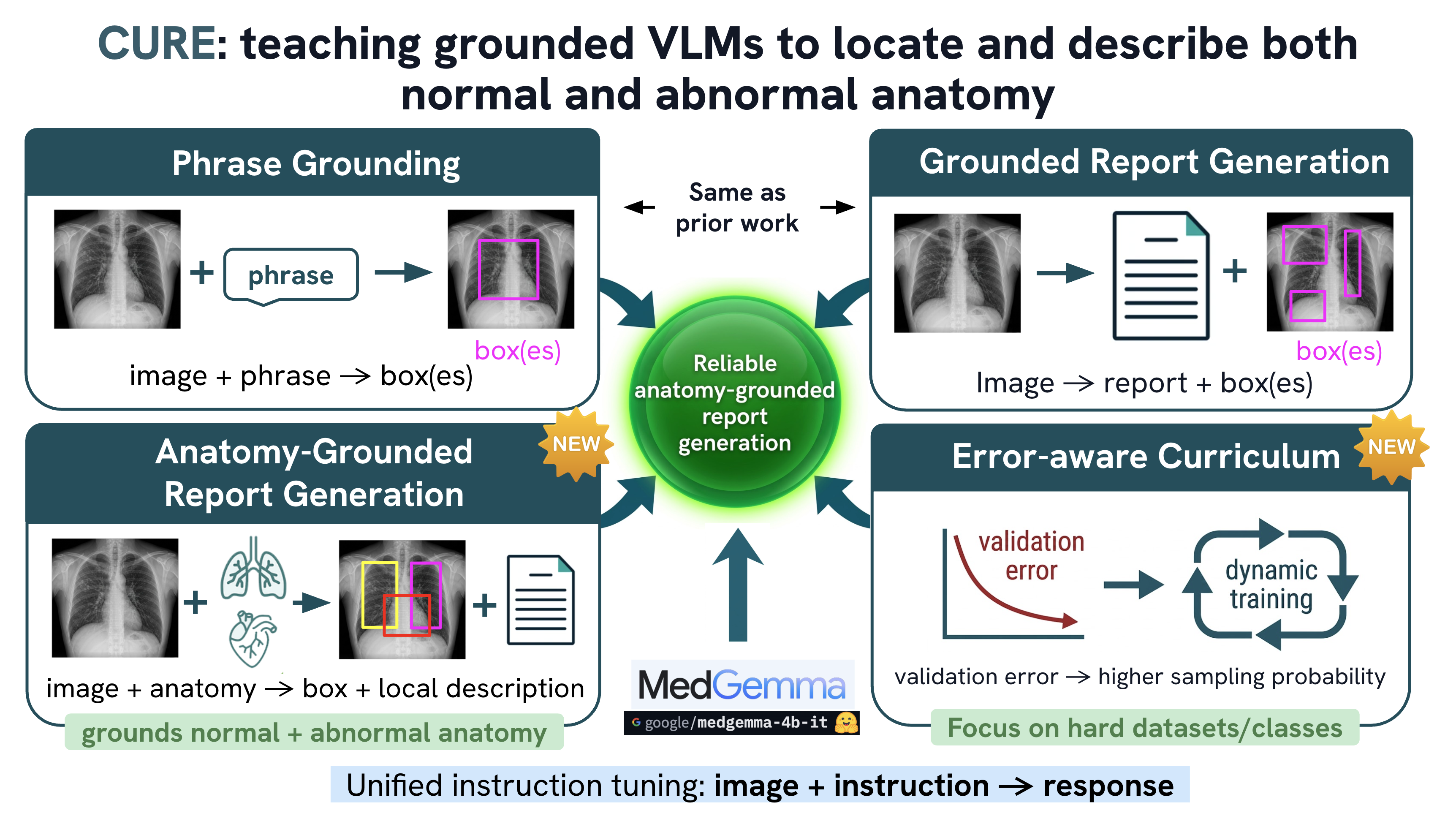
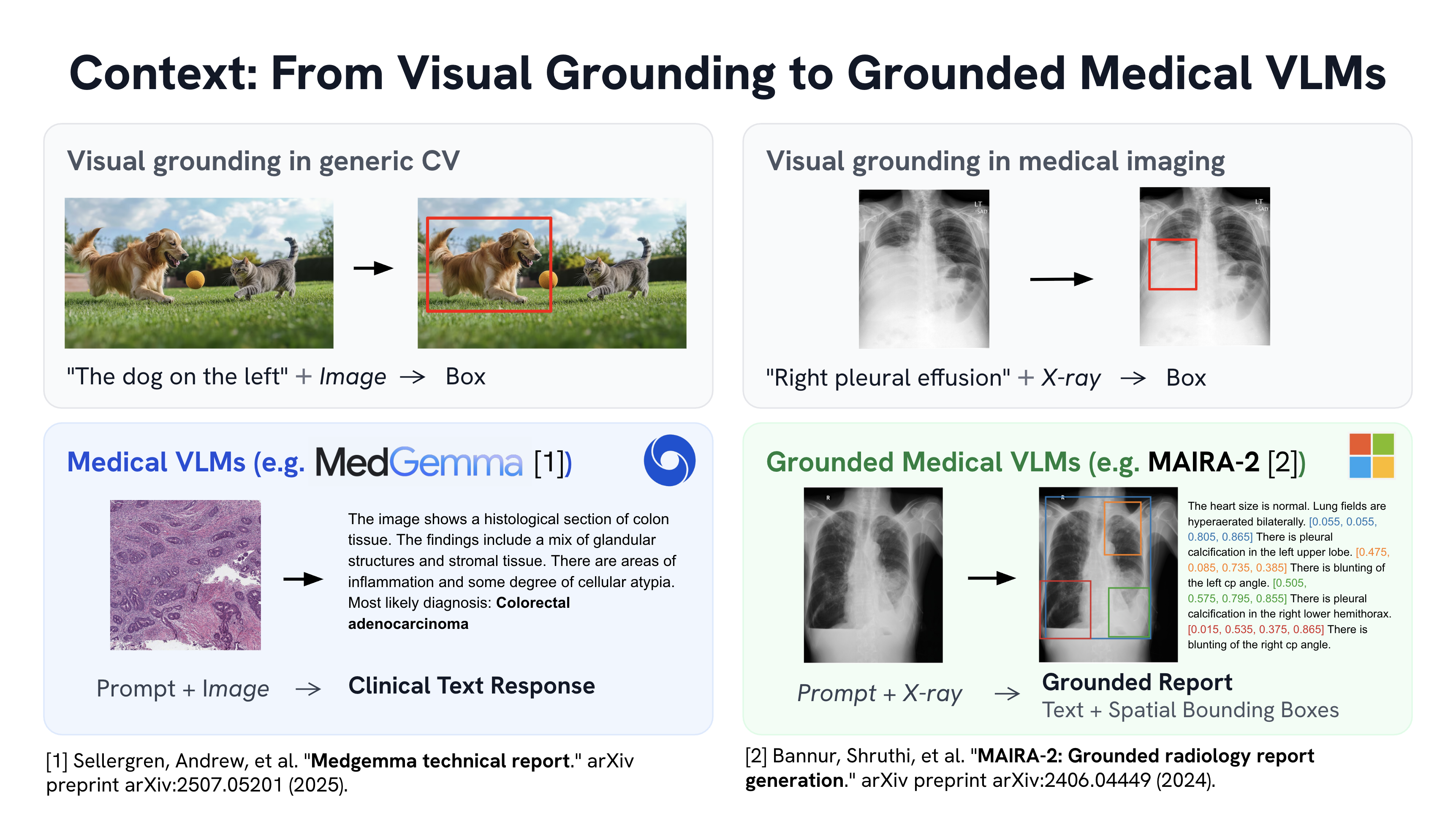
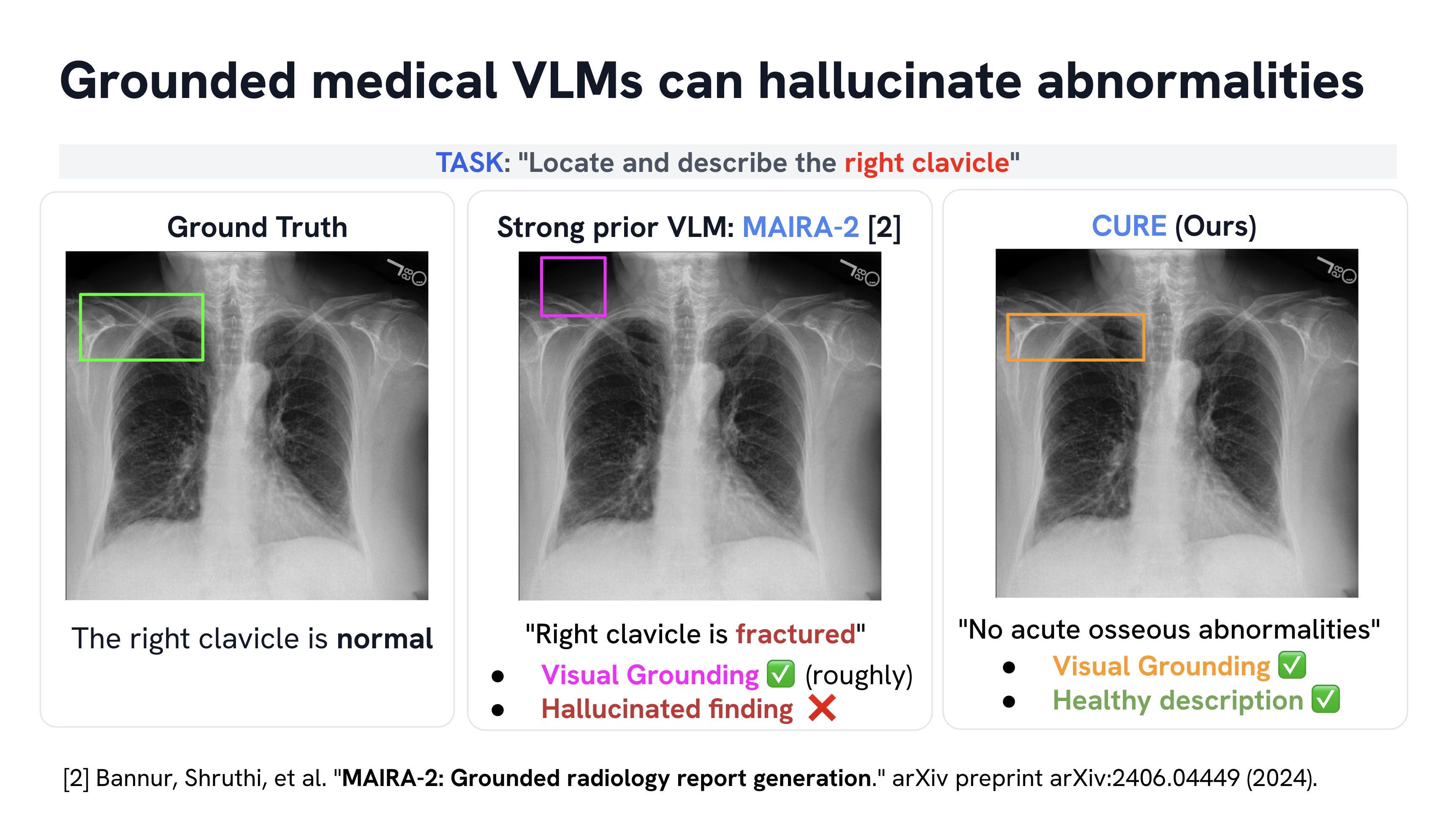
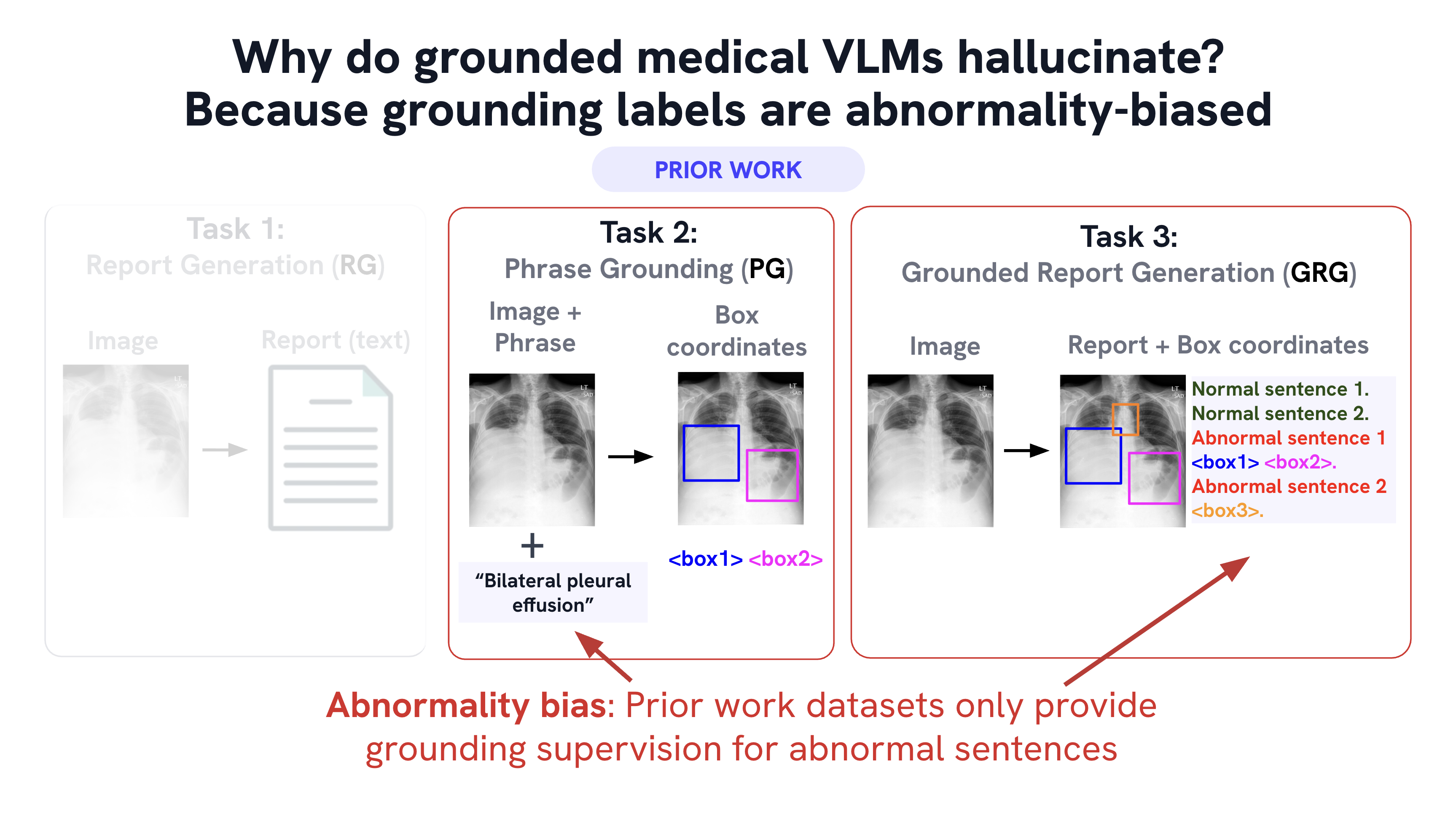
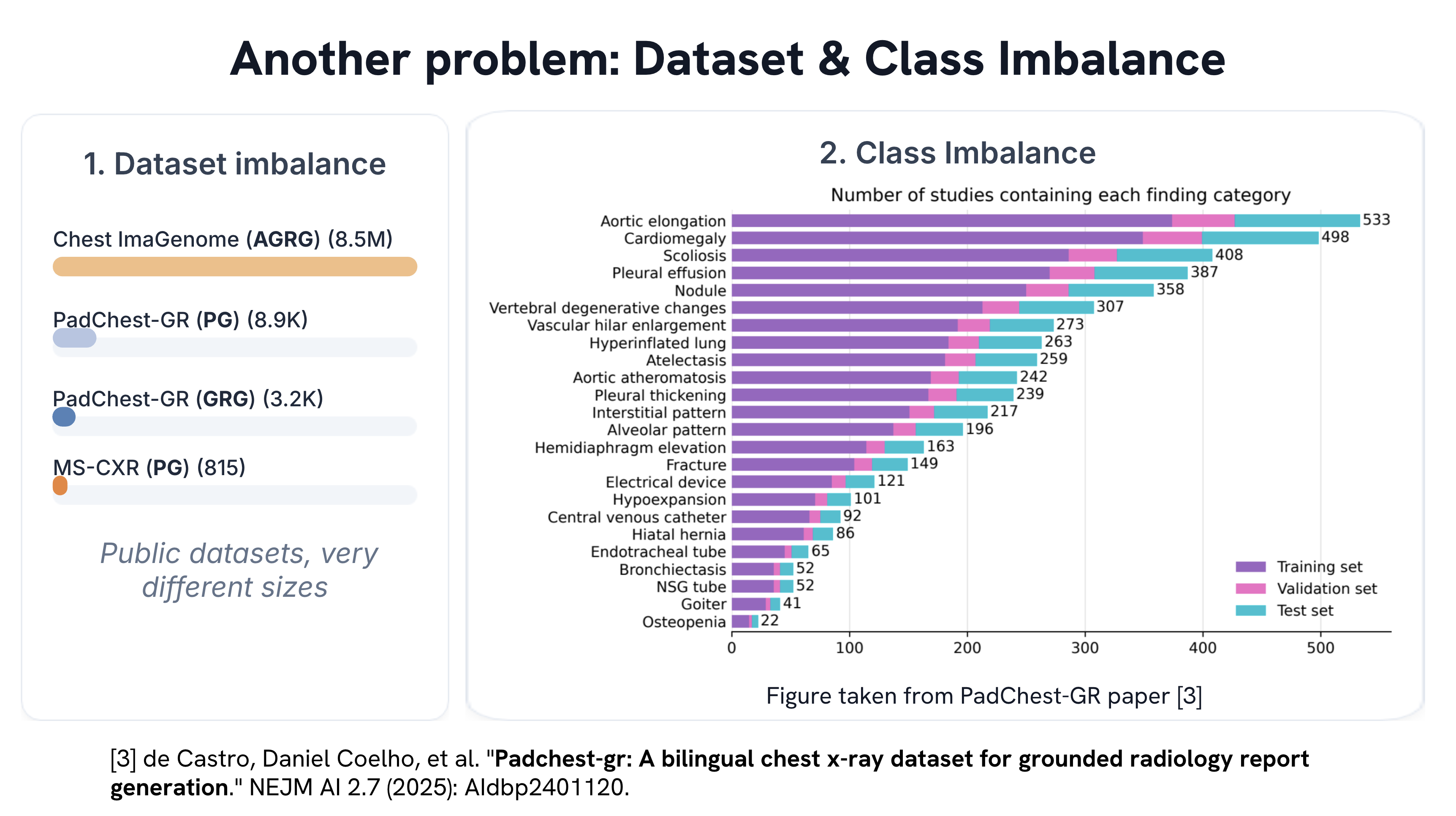
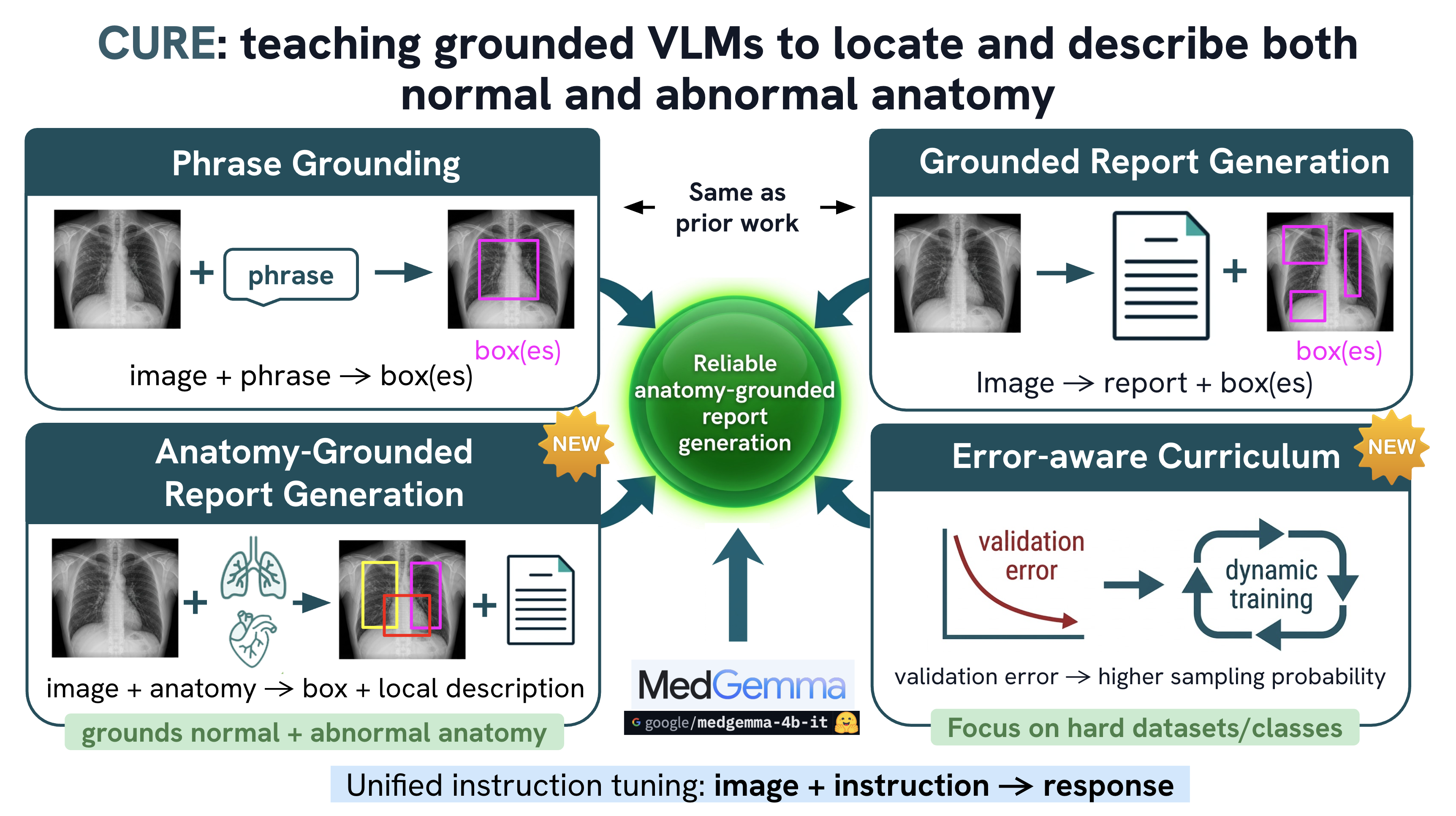
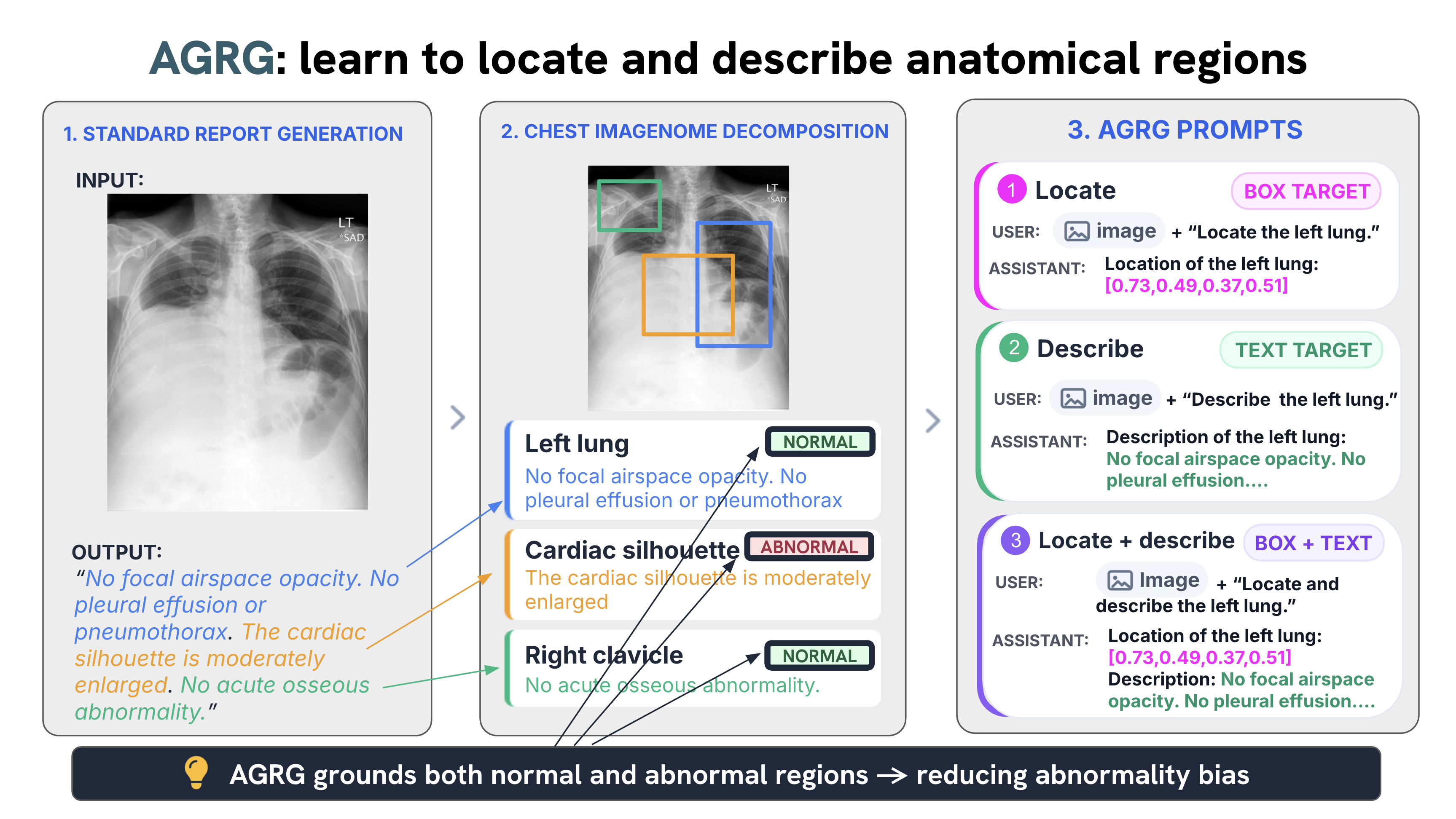
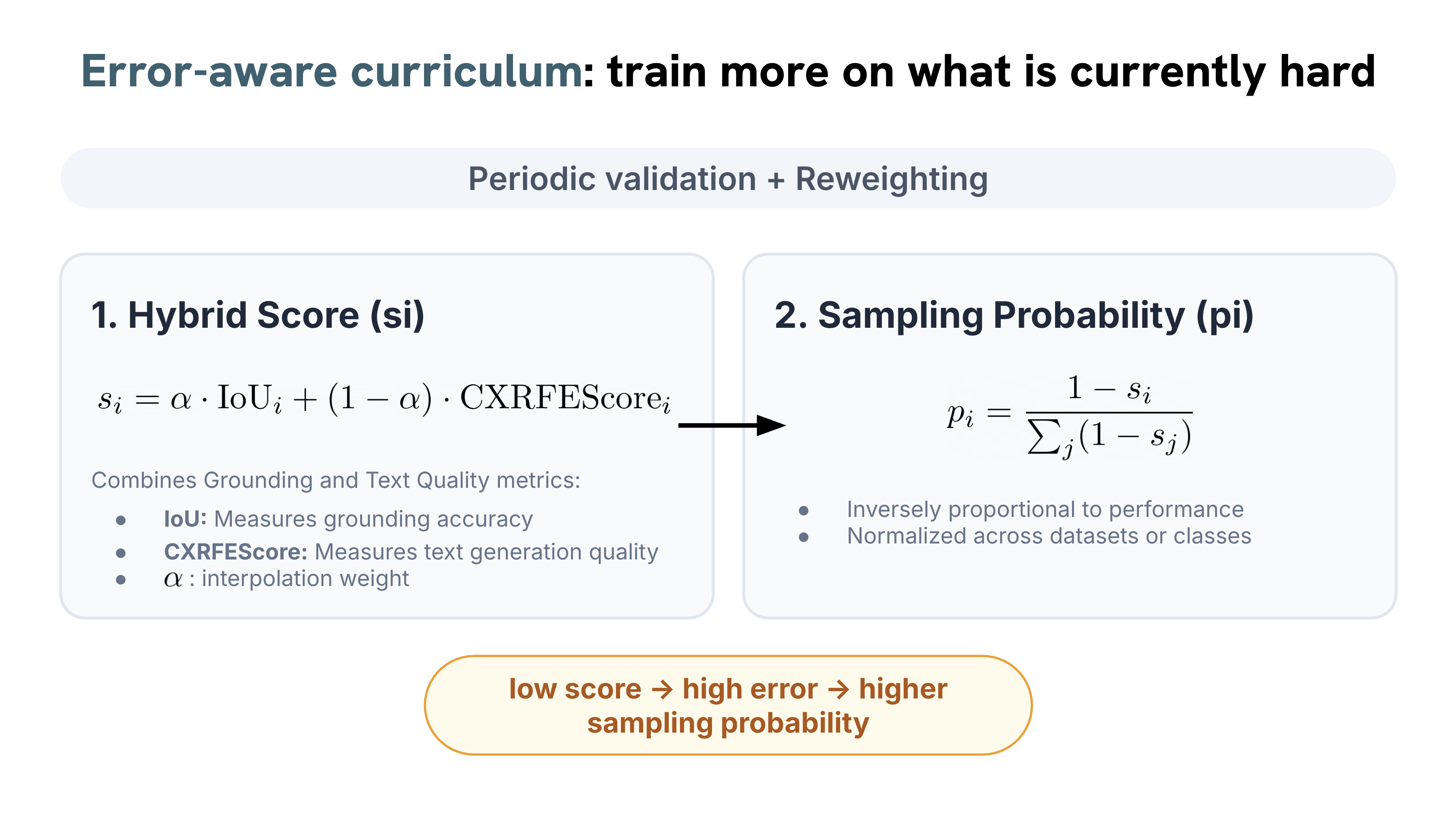
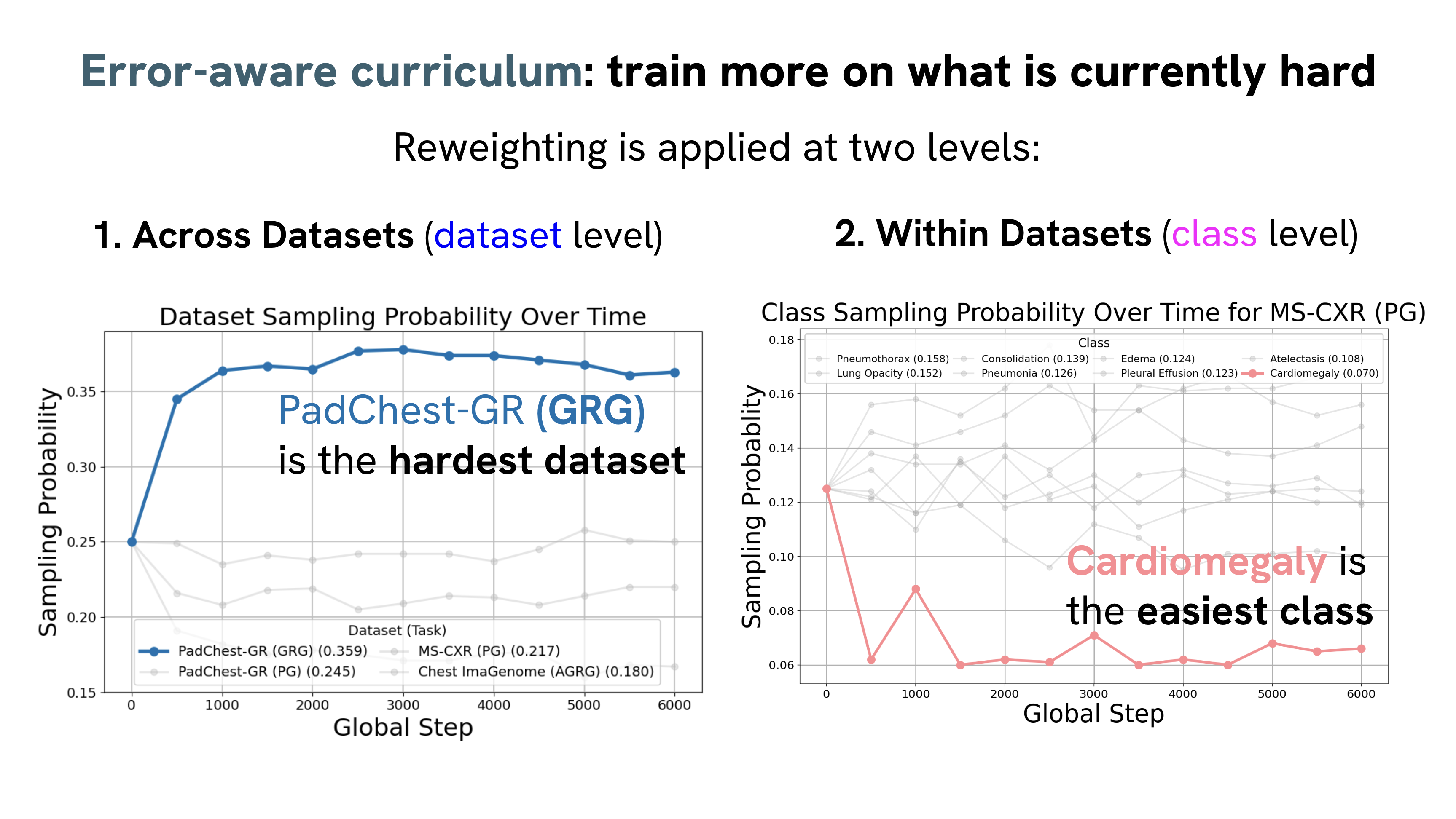
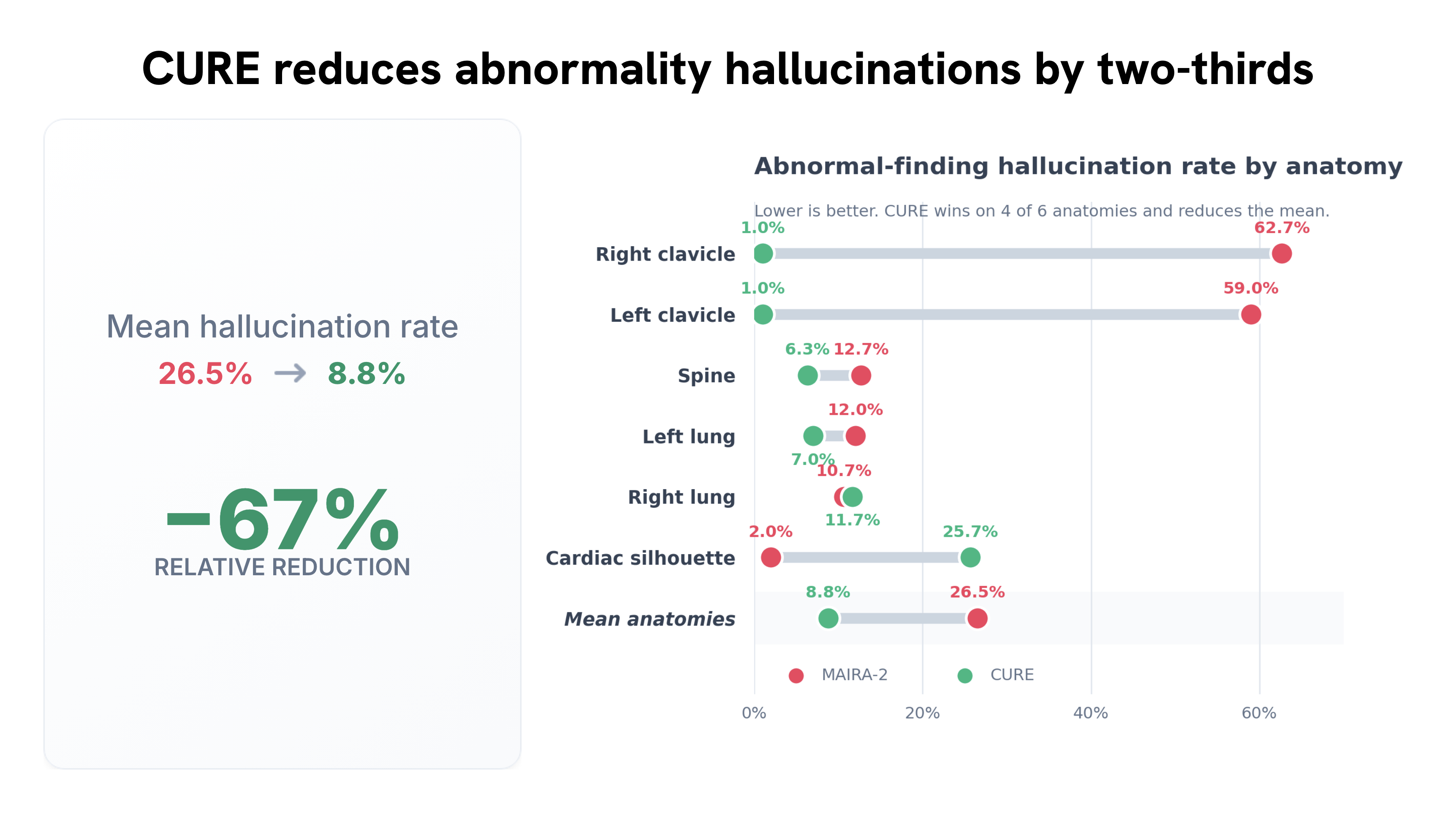
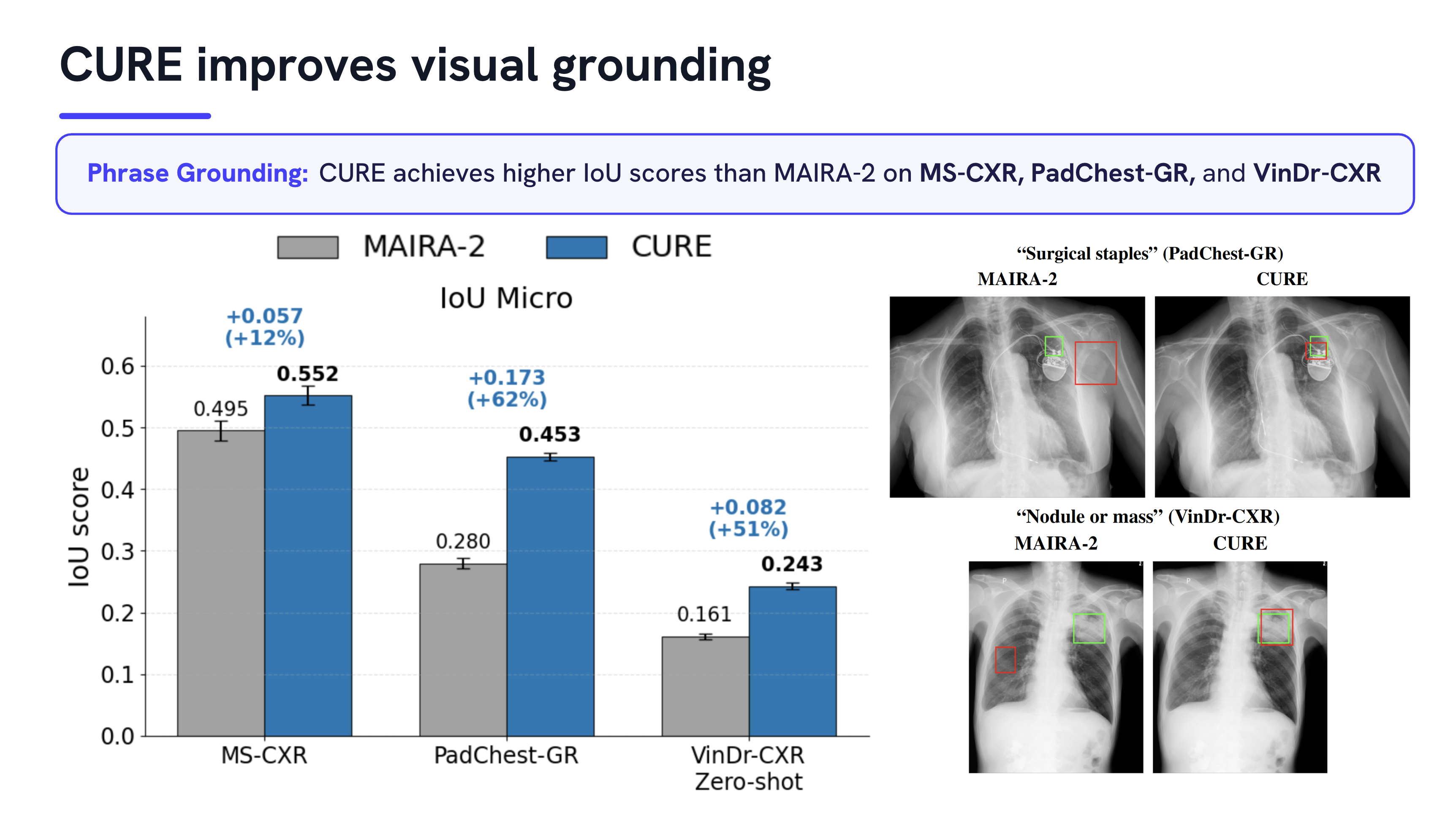
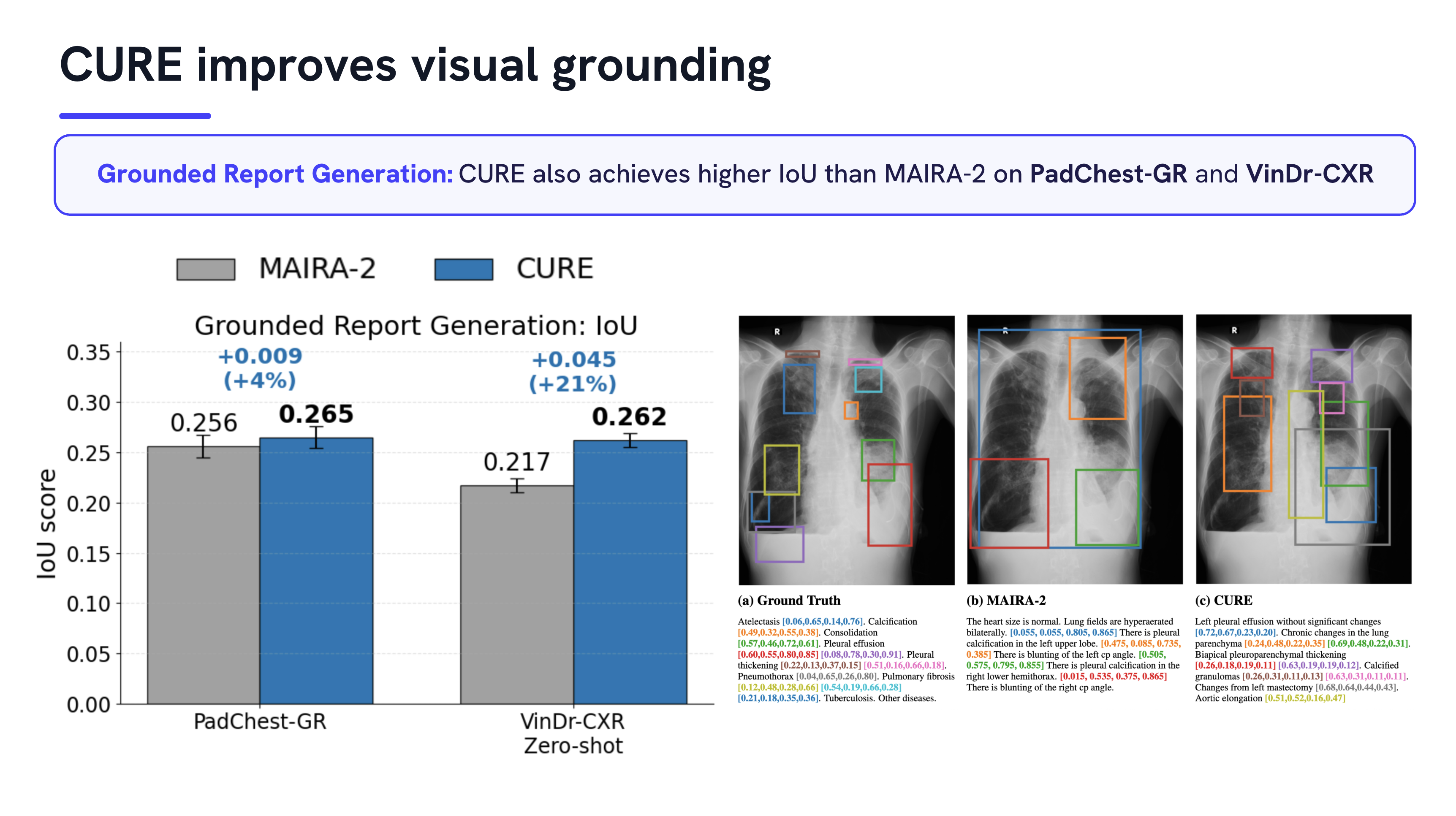
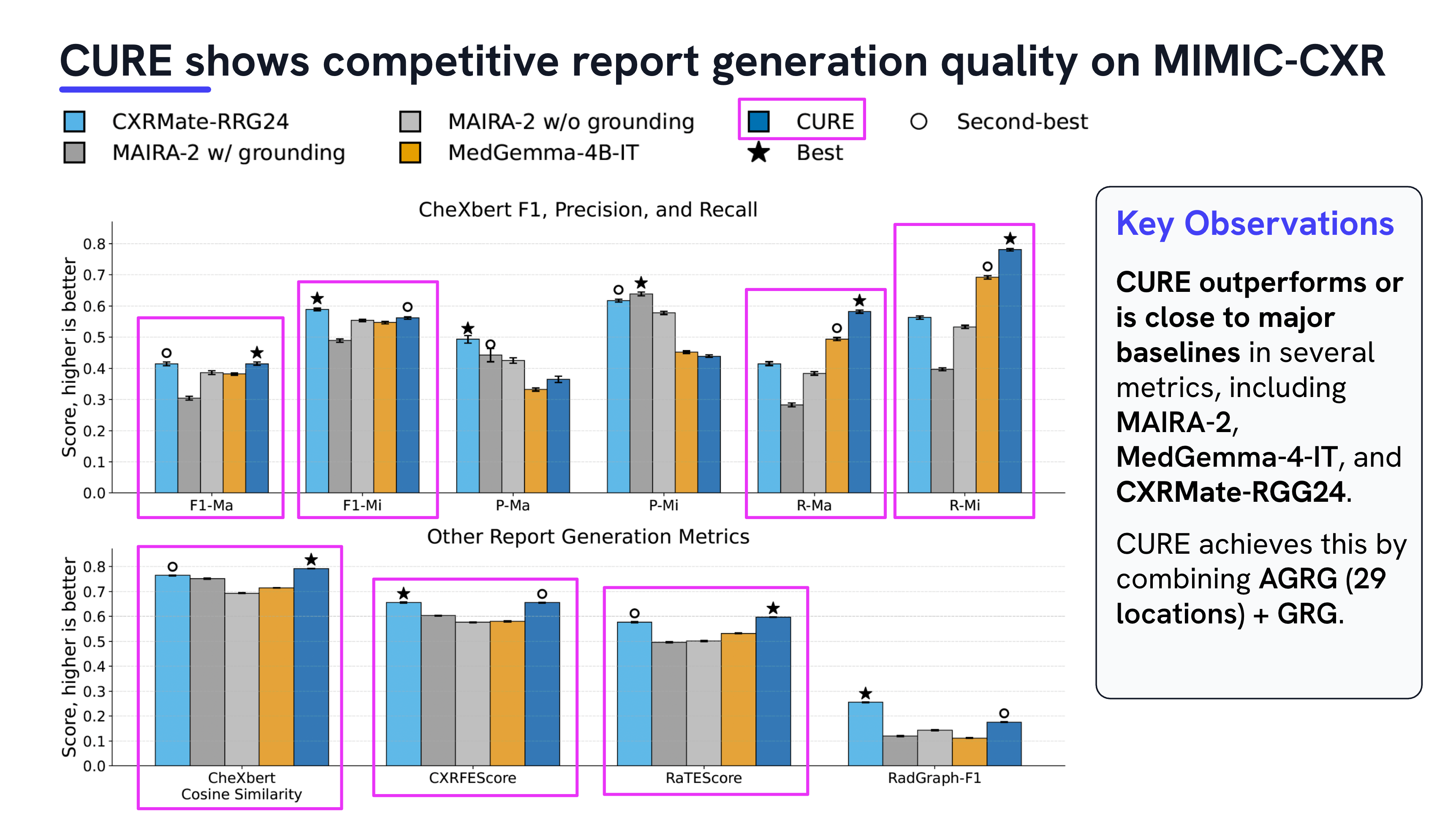
Medical vision–language models can automate the generation of radiology reports but struggle with accurate visual grounding and factual consistency. Existing models often misalign textual findings with visual evidence, leading to unreliable or weakly grounded predictions. We present ``CURE'', an error-aware curriculum learning framework that improves grounding and report quality without any additional data. CURE tunes a multimodal instructional model on phrase grounding, grounded report generation, and anatomy-grounded report generation using public datasets. The method dynamically adjusts sampling based on model performance emphasizing harder samples to improve spatial and textual alignment. CURE improves grounding accuracy by +0.35 IoU, boosts report quality by +0.192 CXRFEScore, and reduces hallucinations by 18.6%. CURE is a data-efficient framework that enhances both grounding accuracy and report reliability. Code is available at https://github.com/PabloMessina/CURE and model weights at https://huggingface.co/pamessina/medgemma-4b-it-cure


This work was conducted while P. Messina was a remote research intern at the Image and Video Understanding Lab (IVUL) at KAUST, under the supervision of B. Ghanem. P. Messina was supported by the ANID Scholarship Program (Doctorado Becas Chile 2019-21191569). We also acknowledge the support of Fondecyt grant 1231724. This work was also funded by ANID - Millennium Science Initiative Program - ICN2021_004 (iHEALTH) as well as ICN17_002 (IMFD), and by the National Center for Artificial Intelligence (CENIA) FB210017, Basal Funds for Centers of Excellence (ANID). The research reported in this publication was supported by funding from King Abdullah University of Science and Technology (KAUST) - Center of Excellence for Generative AI, under award number 5940.
@InProceedings{Messina_2026_CVPR,
author = {Messina, Pablo and Villa, Andr\'es and Alcazar, Juan Leon and Sanchez, Karen and Hinojosa, Carlos and Parra, Denis and Soto, Alvaro and Ghanem, Bernard},
title = {CURE: Curriculum-guided Multi-task Training for Reliable Anatomy Grounded Report Generation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2026},
pages = {36279-36289}
}